BSDiff はバイナリ差分を扱うプログラムです。bsdiffとbspatchの二つのコマンドから成ります。bsdiffは旧ファイルと新ファイルを比較してパッチファイルを出力します。bspatchは旧ファイルにパッチファイルを適用して新ファイルを出力します。コマンドライン引数はbsdiff、bspatch共に旧ファイル、新ファイル、パッチファイルの三つをその順番で指定します。
- Usage: bsdiff oldfile newfile patchfile
- Usage: bspatch oldfile newfile patchfile
BSDiffは実行ファイルの修正差分を取ることを念頭に置いて設計されています。
一般にソースコードのある行に修正を加えた場合、実行ファイルの変化はその修正した行に直接対応する部分だけに留まりません。その行をコンパイルして出来たコード(マシン語列)の長さが変化するからです。その結果、その後に続くコードやデータの位置が前後にずれ、それを参照する命令のアドレス部が変化します。相対アドレスであっても修正した部分をまたぐ参照があった場合は変化します。また、変数や関数の使用状況の変化によって何らかの割り当て値がずれることも考えられます。そのような理由によって、ソースコードのごく一部に加えた修正は実行ファイル全体の広範囲にまばらに変化を引き起こします。
相対アドレスのずれはほとんどの場合一定の量になります。例えば「reljump, 6, dec, a, reljump, 2, inc, a, inc, b」という命令列があった場合、[inc, a]の前に[inc, c]を追加すると「reljump, 8, dec, a, reljump, 4, inc, c, inc, a, inc, b」のように実行ファイルは変化します。このとき、reljump命令のオペランドは6→8、2→4と同じ数(この場合2)だけ変化します。ジャンプ先の前に「inc, c」の2バイトが追加され、以降のコードが2バイト後ろにずれたからです。
このような性質に対応するため、BSDiffでは差分をADDとINSERTという二つの操作としてパッチファイルへ記録します。
ADDは旧ファイルの内容とパッチファイルの内容を足して新ファイルの内容とする操作です。例えば、旧ファイルに「1 5 3 8」という列があって、パッチファイルに「2 2 100 100」という列があった場合、「1+2 5+2 3+100 8+100」という具合に二つを加算して「3 7 103 108」が新ファイルに書き込まれることになります。単純に旧ファイルの一部を新ファイルへコピーしたい場合は「0 0 0 0」とすれば良いわけです。変化の無い部分は0の羅列がパッチファイルに記録されることになりますが、これはlibbz2で大変良く圧縮できます。また、上述した変化量が一定となる変化も、同じ数の羅列になるため良く圧縮できます。
INSERTはパッチファイルの内容をそのまま新ファイルへ挿入する操作です。これは純粋な新規のコード追加に対応します。
上のreljumpの例をパッチに直してみると、次のようになります。
- ADD [0, 2, 0, 0, 0, 2]
- INSERT [inc, c]
- ADD [0, 0]
一般にはADDとINSERTは交互に繰り返されるため、実際には次のようなパッチになります。
- ctrlブロック(ADD長, INSERT長, 旧ファイル内での参照位置の移動量)
- 6, 2, 0
- 2, 0, 0
- diffブロック
- 0, 2, 0, 0, 0, 2,
- 0, 0
- extraブロック
- inc, c
パッチを適用するときはctrlブロックを先頭から読んでいき、次のように新ファイルを生成します。
- ADD操作:diffブロックから6バイト読み取って旧ファイルの先頭6バイトと加算して新ファイルへ出力(旧ファイル内での参照位置を+6進める)
- INSERT操作:extraブロックから2バイト読み取ってそのまま新ファイルへ出力
- 旧ファイル内での参照位置を+0修正(この例では移動の必要が無い)
- ADD操作:diffブロックから2バイト読み取って旧ファイルの6バイト目から2バイトと加算して新ファイルへ出力(旧ファイル内での参照位置を+2進める)
- INSERT操作:長さ0なので何もしない
- 旧ファイル内での参照位置を+0修正(この例では移動の必要が無い)
- 終了
パッチファイルフォーマット
bsdiffが出力するパッチファイルの形式は次のようになっています。
- ファイルヘッダー
- char[ 8 ] "BSDIFF40"
- int64 ctrlブロックの圧縮後サイズ
- int64 diffブロックの圧縮後サイズ
- int64 新しいファイルのサイズ(パッチを当てた後のサイズ)
- 圧縮されたctrlブロック (int64,int64,int64)*(ctrlブロックの展開後サイズ/(8*3))
- 圧縮されたdiffブロック
- 圧縮されたextraブロック
圧縮にはbzip2(libbz2)を使います。全体を一括では無く、ファイルヘッダーを除く三つのブロックをそれぞれ個別に圧縮します。
ctrlブロックは次の三つの値が一つのエントリーになっています。
- ADD操作の長さ
- INSERT操作の長さ
- 旧ファイル内での現在位置の移動量
パッチの実行はctrlブロックからエントリーを読み出していって、一つのエントリー毎に次の処理を行います。
- ADD操作 : diffブロックから「ADD操作の長さ」分だけバイト列を取り出し、それを旧ファイル内での現在位置から続くバイト列とバイト毎に足し合わせて新ファイルとして出力
- INSERT操作 : extraブロックから「INSERT操作の長さ」分だけバイト列を取り出し、それをそのまま新ファイルとして出力
- 旧ファイル内での現在位置を「旧ファイル内での現在位置の移動量」だけ加算
これを実行するのがbspatchです。
bspatch.c
以下のコードは http://opensource.apple.com/source/X11server/X11server-106.3/Sparkle/sparkle.git/bspatch.c のbspatch関数から引用したものです。本家よりファイル読み込み部分が抽象化されていて分かりやすいので。日本語のコメントは私が書き加えました。
// oldposやnewpos、ctrl[n]など、ほとんどの変数はoff_t型(64-bit符号付き整数) // ssize_t newsize = 新ファイルのサイズ // u_char *new = 新ファイルの書き込み先バッファ先頭 // ssize_t oldsize = 旧ファイルのサイズ // u_char *old = 旧ファイル全体のバイト列 oldpos=0;newpos=0; while(newpos<newsize) { /* Read control data */ for(i=0;i<=2;i++) { lenread = io->read(cstream, buf, 8); if (lenread < 8) errx(1, "Corrupt patch\n"); ctrl[i]=offtin(buf); // offtinはchar[8]からoff_tへ変換する関数 }; /* Sanity-check */ if(newpos+ctrl[0]>newsize) //ctrl[0]が負の時に漏れてしまうのでは? errx(1,"Corrupt patch\n"); /* Read diff string */ lenread = io->read(dstream, new + newpos, ctrl[0]); if (lenread < ctrl[0]) errx(1, "Corrupt patch\n"); /* Add old data to diff string */ for(i=0;i<ctrl[0];i++) if((oldpos+i>=0) && (oldpos+i<oldsize)) new[newpos+i]+=old[oldpos+i]; /* Adjust pointers */ newpos+=ctrl[0]; oldpos+=ctrl[0]; /* Sanity-check */ if(newpos+ctrl[1]>newsize) //ctrl[1]が負の時に漏れてしまうのでは? errx(1,"Corrupt patch\n"); /* Read extra string */ lenread = io->read(estream, new + newpos, ctrl[1]); if (lenread < ctrl[1]) errx(1, "Corrupt patch\n"); /* Adjust pointers */ newpos+=ctrl[1]; oldpos+=ctrl[2]; };
ループの中はおおむね次のようになっています。
- コントロールデータ読み込み ctrl [ 0 ] ~ ctrl [ 2 ]
- ADD操作
- diffsize = ctrl[ 0 ]
- diffblockからdiffsizeだけ読み込む(new+newposへ)。
- バイト毎の加算 new[newpos..<newpos+diffsize] += old[oldpos..<oldpos+diffsize] (oldposの範囲が有効な場合に限り)
- newpos += diffsize
- oldpos += diffsize
- INSERT操作
- extrasize = ctrl[ 1 ]
- extrablockからextrasizeだけ読み込む
- newpos += extrasize
- oldpos += ctrl [ 2 ]
bsdiff.c
それで肝心のパッチファイルを作る、つまり、バイナリ差分を作成するアルゴリズムはどのようになっているのでしょうか。
大きく分けて、二つの重要な技術的なポイントがあります。
- 新ファイルのある部分にマッチする旧ファイルの部分を高速に探す方法
- パッチファイルが小さくなるようなマッチング範囲の決定方法
一つ目は一種の全文検索の問題です。つまり、新ファイルのある場所から始まる文字列をキーに旧ファイル内を検索するわけです。それには接尾辞配列という索引を使い、その作成に接尾辞ソートを用います。接尾辞配列については Wikipedia に解説があります。ソートにはLarsson Sadakane法が使われているらしいです。
二つ目。新旧の対応関係が探せればあとは「旧データのどこから何バイトコピー、新データから何バイトコピー」といったデータを羅列していけば良いだけに思うかもしれませんが、話はそう簡単ではありません。私たちが欲しいのは最小のパッチファイルです。ある新旧のファイルがあったとき、旧から新を生成するパッチは一通りとは限りません。上述したように実行ファイルの変化は全体にまばらに広がっているので、下手にやると一致箇所と不一致箇所が細かく繰り返され、大変非効率なパッチになりかねません。上述したコントロール(ADD/INSERT操作)の回数が少ないほど余分なオーバーヘッドが小さくなりパッチファイルのサイズは小さくなるわけですが、そのような組み合わせをどのように求めたら良いでしょうか。全ての可能性を試すには膨大な時間が必要で現実的ではなさそうです。
BSDiffでは新旧が一致している部分(変更が無い部分)は旧から新へのベタCOPYではなくADD操作によって表現します。従って、1回のADD操作の中で多少の不一致部分が含まれていてもそれほど問題になりません。むしろ、一回のADDにまとめてしまった方が効率的な場合もあります。つまり、厳密な一致箇所・不一致箇所を求めるのでは無く、ある程度おおまかなマッチングを行います。これをBDiffでは近似一致(approximate matches)と呼んでいます。 つまり、新ファイルの先頭から末尾までスキャンしていきながら、旧ファイルとの間で近似的な一致範囲、ならびに同じく近似的な不一致範囲を求めていきます。そして近似一致をADD操作として、近似不一致をINSERT操作として出力していくことになります。
それでは bsdiff.c を見ていきましょう。(オンラインで本家のソースを見られるところがあまり無いので、Debianのbsdiffパッケージのソースへリンクしています)
main関数の流れは次のようになっています。
- 旧ファイルの読み込み(old, oldsize)
- 索引の作成(I) qsufsort(I,V,old,oldsize)呼び出し(Vはテンポラリ)
- 新ファイルの読み込み(new, newsize)
- ファイルヘッダーを仮出力(ブロックサイズはまだ分からないので0で仮出力)
- 差分を求める(db,eb,dblen,eblen)と同時にctrlブロックを書き出す
- 5で求めたdiffブロック(db)を書き出す
- 5で求めたextraブロック(eb)を書き出す
- ファイルヘッダーの書き直し(diffブロックとextraブロックの圧縮後サイズを書き直す)
- 終了
複雑なのは5の差分を求める部分です。
2と5を合わせてC++風にして余分なものを分離して分かりやすく変形してみました。
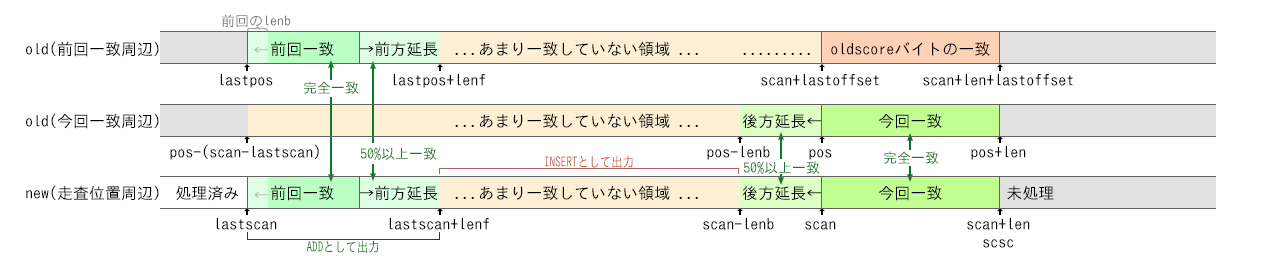
static void bsdiff( u_char * const olddata, const off_t oldsize, u_char * const newdata, const off_t newsize, std::function<void(off_t, off_t, off_t)> writeCtrl, std::vector<u_char> &db, std::vector<u_char> &eb) { // 検索に必要な索引を作る std::unique_ptr<off_t[]> I(new off_t[oldsize+1]); { std::unique_ptr<off_t[]> V(new off_t[oldsize+1]); qsufsort(I.get(),V.get(),olddata,oldsize); } // 出力バッファを準備 db.clear(); db.reserve(newsize+1); eb.clear(); eb.reserve(newsize+1); // 新ファイルを先頭から末尾へスキャンしていきながら、新ファイルの領域が旧ファイルのどの領域と対応づけられるか決めていく。 // 領域の対応関係が確定したら、その領域のパッチをwriteCtrl,db,ebへ出力。 off_t scan=0; //調べているnew上の位置 off_t lastscan=0; //前回一致のnew上の先頭。出力し終わったnew上の末端 off_t lastpos=0; //前回一致のold上の先頭 off_t lastoffset=0; //new上の位置からold上の位置を求めるための差(lastpos-lastscan) while(lastscan < newsize){ // 切れ目を見つける。 off_t len=0; off_t pos; for(off_t scsc=scan, oldscore=0; scan<newsize;) { // old 内から new[scan...newsize) との最長一致を探す。 // posはその位置、lenはその長さ。 // old[pos...pos+len) == new[scan...scan+len) となる。 len=search(I.get(),olddata,oldsize,newdata+scan,newsize-scan, 0,oldsize,&pos); // oldscoreを差分的に更新する。 // oldscoreは今回一致範囲[scan...scan+len)と前回一致の続きとの一致バイト数。 // scscをscan+lenまで進めることによる増加分を数える。 for(;scsc<scan+len;scsc++) if((scsc+lastoffset<oldsize) && (olddata[scsc+lastoffset] == newdata[scsc])) oldscore++; // 前回一致の前方延長が新旧完全に一致しているので、その前方延長を継続。 if(len == oldscore && len != 0){ scan += len; scsc = scan; oldscore = 0; continue; } // 前回一致の前方延長に9バイト以上の不一致があり(len-oldscore > 8)、 // 他の場所に9バイト以上の完全一致が見つかった(len > 8) // ので、参照する旧領域を切り替える。 if(len>oldscore+8) break; // oldscoreを差分的に更新する。 // scanを1進めることによる減少分。 if((scan+lastoffset<oldsize) && (olddata[scan+lastoffset] == newdata[scan])) oldscore--; ++scan; } // 近似的な一致・不一致の境界線を定める。 // 前回一致の先頭(lastpos)から前方へ、あまり変化していない長さを求める。 // 一致を50%以上含んでいて、一致がある程度多くなっていればどんどん延ばす。 off_t lenf=0; for(off_t i=0,s=0,Sf=0;(lastscan+i<scan)&&(lastpos+i<oldsize);) { if(olddata[lastpos+i]==newdata[lastscan+i]) s++; i++; if(s*2-i>Sf*2-lenf) { Sf=s; lenf=i; }; }; // 今回一致の先頭(pos)から後方へ、あまり変化していない長さを求める。 // 一致を50%以上含んでいて、一致がある程度多くなっていればどんどん延ばす。 off_t lenb=0; if(scan<newsize) { for(off_t i=1,s=0,Sb=0;(scan>=lastscan+i)&&(pos>=i);i++) { if(olddata[pos-i]==newdata[scan-i]) s++; if(s*2-i>Sb*2-lenb) { Sb=s; lenb=i; }; }; }; // 前回一致の前方延長と今回一致の後方延長が重なっているなら、 // 前回一致の前方延長を優先しつつ、境目を確定させる。 if(lastscan+lenf>scan-lenb) { off_t overlap=(lastscan+lenf)-(scan-lenb); off_t Ss=0,lens=0; for(off_t i=0,s=0;i<overlap;i++) { if(newdata[lastscan+lenf-overlap+i]== olddata[lastpos+lenf-overlap+i]) s++; if(newdata[scan-lenb+i]== olddata[pos-lenb+i]) s--; if(s>Ss) { Ss=s; lens=i+1; }; }; lenf+=lens-overlap; lenb-=lens; }; // 差分を出力する。(deltaブロック、extraブロック、ctrlブロックへ) // ADD操作: new[lastscan...lastscan+lenf) - old[lastpos...lastpos+lenf) をdiffブロックへ出力 for(off_t i=0;i<lenf;i++) db.push_back(newdata[lastscan+i]-olddata[lastpos+i]); // INSERT操作: new[lastscan+lenf...scan-lenb) をextraブロックへ出力 for(off_t i=0;i<(scan-lenb)-(lastscan+lenf);i++) eb.push_back(newdata[lastscan+lenf+i]); writeCtrl( lenf, //ADD長 (scan-lenb)-(lastscan+lenf), //INSERT長 (pos-lenb)-(lastpos+lenf)); //旧ファイルの現在位置を pos-lenb へ移動 lastscan=scan-lenb; //ここまで新ファイルを出力 lastpos=pos-lenb; //lastscanに対応するold上の位置 lastoffset=pos-scan; //新ファイル上の位置から旧ファイル上のマッチする位置へ変換するための差(scan+i + lastoffset は pos+iに対応する) scan += len; } }
案外複雑ですね。ループを何回か追ってみないと何をしているのかよく分からないかもしれません。
新ファイルの内容が全て出力されるようなコントロール(ADD/INSERT操作列)を出力し終わったら一番外側のループは終了です。
一番外側のループ内では次のことをします。
-
大まかに一致・不一致範囲(領域の境目)を特定します。
まずnew[scan]から続くバイト列と一致するoldの位置と長さを求めます。
そしてoldの前回一致した領域の末尾(無ければ先頭)からその長さ分だけnewのscan位置と比較し、9バイト以上不一致がある場合、そこを大まかな境界線と考えて2へ。
9バイト以上不一致が無い、つまり、oldの前回一致した領域から続く列とnewのスキャン位置がそれほど違っていない場合、まだ前回からの一致が続いているものと考えて、scanを1進めて探索を繰り返します。
-
一致・不一致範囲を確定させます。
50%以上の一致率を目安に、 前回 一致した領域を前方に延ばした場合の長さを求めます(lenf)。
同じく50%以上の一致率を目安に、 今回 一致した領域を後方(backward:先頭へ戻る方向)に延ばした場合の長さを求めます(lenb)。
前回 一致した領域からlenfだけ前方へ延ばしたところが 今回 出力する近似一致領域の末尾です。
今回 一致した領域からlenbだけ後方へ延ばしたところが 次回 出力する近似一致領域の先頭です。
その間の一致率の低い領域が新領域だけに存在すると考える、今回出力する近似不一致領域です。
-
コントロールを出力します。
一致領域をADD操作としてdiffブロックへ、不一致領域をINSERT操作としてextraブロックへ、その長さと次の一致箇所への相対位置をctrlブロックへ出力します
かいつまんで言うと、新旧で完全に一致する領域を見つけていき、その前後にあるあまり変化していない(まばらに違いがある)領域をその一致領域に含めていく感じでしょうか。そして、その一致領域の間にある領域を不一致領域とします。
各変数の位置関係はおおむね次図のようになります。
bspatchの脆弱性
bspatch.c を読んでいて気がついたのですが、bspatch.cのSanity-checkと書いてある部分は読み込んだctrlの値(off_t 64-bit符号付き整数)が負の時にチェックをすり抜けてしまいます。
/* Sanity-check */ if(newpos+ctrl[0]>newsize) errx(1,"Corrupt patch\n");
その値(ctrl[ 0 ])は続く BZ2_bzRead にを読み込みバイト数(int)として引き渡しています。 BZ2_bzReadでは負のバイト数はエラーにしていますが、その前に呼び出し側でoff_tからintへの変換が生じます。 intが32-bitのときは上位の桁が失われますので、ctrl[ 0 ]が0x8000000100000001のような値の時は、BZ2_bzReadは1バイト読み込みで通ってしまうのではないでしょうか? その後newpos += ctrl [ 0 ]ですから、ポインターが64-bitのときはnew+newposはバッファの外を指してしまいそうです。 そしてその後、バッファーオーバーランを引き起こす気がします(LP64,LLP64時)。
AndroidやChromeなどいくつかのプロジェクトでは修正を行っているようですが、修正されていないものも多く見られます(上のリンク先のもそうですね)。
- bspatch.c | review.cyanogenmod Code Review
- Diff - 4d054795b673855e3a7556c6f2f7ab99ca509998^! - platform/external/bsdiff - Git at Google
- Issue 372525 - chromium - Security: heap write access due to integer overflow on bspatch implementations - An open-source project to help move the web forward. - Google Project Hosting
元々実行ファイルへのパッチを信頼できないところから取得するというのは考えづらいとは思いますが、ゲームのデータに対する野良パッチを拾って適用しようとしたらそのデータ以外もおかしな事になった、というような事は考えられるかもしれません。十分注意したいものです。
Chromeにおける改良
Chromeでは修正差分の配布にこのbsdiffを改良したものを使っているらしいです。
- Software Updates: Courgette - The Chromium Projects
- master - chromium/src/courgette - Git at Google
- third_party - chromium/src/courgette - Git at Google : Courgetteのbsdiffから派生した部分
そういえば何年か前にニュースになっていたような気もします。
Courgetteでは実行ファイルを逆アセンブルして一段階ソースコードに近い状態に戻すことで、アドレスにまつわる問題を低減しているんだそうです。 master - chromium/src/courgette - Git at Google を見ても、CPUアーキテクチャに依存していそうなファイル名が並んでますね。
参考URL
- Binary diff (本家Colin Percival作)
- bsdiff-4.3.tar.gz
- Naïve Differences of Executable Code BSDiffの原理に言及したペーパー
- mendsley/bsdiff - C (Matthew Endsleyの改造版)
- http://opensource.apple.com/source/X11server/X11server-106.3/Sparkle/ にある多少改変されているソース(本家にはないコメントが参考になるかも?)
- 接尾辞配列について
- bzip2