org-modeのテーブル(表、スプレッドシート)に数式を入力する方法として C-c = (org-table-eval-formula) や C-c ' (org-table-edit-formulas)があります。(参照: Editing and debugging formulas (The Org Manual))
C-c ' は別バッファに数式を表示してそれを編集できるようにします。数式入力用のバッファ内では、ポイントが当たっている(フィールド/カラム)参照やその参照先をハイライトする機能もあります。また、Shift+矢印キーで参照先を変更する機能もあります。
一方 C-c = はミニバッファから数式を入力するので手軽ですが、 C-c ' で使える便利な機能が使えません。しかしミニバッファといえどもEmacsのバッファではあるので C-c ' で開く数式編集バッファと同じ事ができない理由はありません。
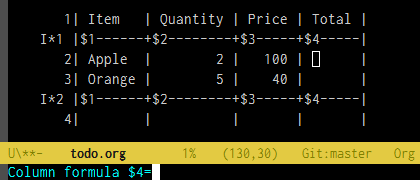
また、前回少し言及したように、何も入力していない段階でShift+矢印キーを押したときに新しい参照を新規で追加できるようになっていれば C-c = S-<left> S-<left> * S-<left> というキー操作で $4=$2*$3 を入力するようなことができるはずです。これができれば座標(列番号)を数える必要性はグッと減ります。
というわけで書いたコード:
数式入力ミニバッファの改善
まずはorg-table-eval-formula(C-c =)でのミニバッファ入力中にorg-table-edit-formulas(C-c ')と同じキー操作ができるようにします。minibuffer-setup-hookでorg-table-edit-formulasと同等の初期化処理をしてやれば良いでしょう。
;;;; 数式入力ミニバッファの改善 ;; `org-table-eval-formula'(C-c =) のミニバッファ入力中に ;; `org-table-edit-formulas'(C-c ')と同じキー操作ができるようにする。 (defvar my-org-table-formula-minibuffer-map ;; `org-table-fedit-map'から使えそうなものだけを取りだしたキーマップ。 (let ((km (make-sparse-keymap))) (define-key km "\C-c}" 'org-table-fedit-toggle-coordinates) (define-key km [(meta shift up)] 'org-table-fedit-line-up) (define-key km [(meta shift down)] 'org-table-fedit-line-down) (define-key km [(shift up)] 'org-table-fedit-ref-up) (define-key km [(shift down)] 'org-table-fedit-ref-down) (define-key km [(shift left)] 'org-table-fedit-ref-left) (define-key km [(shift right)] 'org-table-fedit-ref-right) (org-defkey km [(meta up)] 'org-table-fedit-scroll-down) (org-defkey km [(meta down)] 'org-table-fedit-scroll) ;; M-S-p等でも操作できるようにしてみる。 (define-key km [(control meta ?p)] 'org-table-fedit-ref-up) (define-key km [(control meta ?n)] 'org-table-fedit-ref-down) (define-key km [(control meta ?b)] 'org-table-fedit-ref-left) (define-key km [(control meta ?f)] 'org-table-fedit-ref-right) km)) (defun my-org-table-eval-formula:around (old-fun &rest args) (let ((pos (point-marker))) (minibuffer-with-setup-hook ;; ミニバッファが開いたときに呼ばれる。 (lambda () ;; 元orgバッファの位置を入力バッファのローカル変数にする。 (setq-local org-pos pos) ;; キー割り当てを追加する。 (use-local-map (make-composed-keymap my-org-table-formula-minibuffer-map (current-local-map))) ;; 参照しているセルをハイライトする。 (add-hook 'post-command-hook #'org-table-fedit-post-command t t)) ;; 元の関数を呼び出す。 (apply old-fun args)))) (advice-add #'org-table-eval-formula :around #'my-org-table-eval-formula:around)
数式入力時のS-矢印キーを改善
次にShift+矢印キーで参照先を移動する機能を改善します。
改善点:
- @だけの場合 (@の後に数字等が無い場合も含む)
- $だけの場合 ($の後に数字等が無い場合も含む)
- 参照が無いところでの新規追加
@<や@>>、@I+1への対応$<や$>>への対応
;;;; 数式入力時のS-矢印キーを改善 ;; `org-table-fedit-shift-reference'(S-矢印キー)を改善する。 ;; - @だけの場合 (@の後に数字等が無い場合も含む) ;; - $だけの場合 ($の後に数字等が無い場合も含む) ;; - 参照が無いところでの新規追加 ;; - @<や@>、@I+1への対応 ;; - $<や$>への対応 (defun my-org-table-fedit-shift-reference (dir) (cond ;; A E&-like reference (Same as $5) ((org-in-regexp "\\(\\<[a-zA-Z]\\)&") (if (memq dir '(left right)) (org-table--rematch-and-replace 1 (eq dir 'left)) (user-error "Cannot shift reference in this direction"))) ;; A B3-like reference ((org-in-regexp "\\(\\<[a-zA-Z]\\{1,2\\}\\)\\([0-9]+\\)") (if (memq dir '(up down)) (org-table--rematch-and-replace 2 (eq dir 'up)) (org-table--rematch-and-replace 1 (eq dir 'left)))) ;; Examples: ;; @1 @+1 @-1 @0 @< @>> @I @+II @-III @I+2 @-II-4 ;; @1$3 @-1$+4 ;; @I..II ;; @I..@II ;; $1 $+1 $-1 $0 $< $>> ((org-in-regexp (concat ;; 1: Row spec "\\(" "\\(?:@\\|\\.\\.\\)" ;; @+I (?2: +1 ) "\\(?:\\(?:[-+]?I+\\([-+][0-9]+\\)\\)" ;; @ (?3: +I | +1 | < | > ) "\\|\\([-+]?\\(?:I+\\>\\|[0-9]+\\)\\|<+\\|>+\\)\\)?" "\\)" ;; 4: Column spec after row spec ;; $ (?5: +1 | < | > ) "\\(\\$\\([-+]?[0-9]+\\|<+\\|>+\\)?\\)?" ;; 6: Column spec alone ;; $ (?7: +1 | < | > ) "\\|" "\\(\\$\\([-+]?[0-9]+\\|<+\\|>+\\)?\\)")) (cond ;; Up or Down ((memq dir '(up down)) (cond ((match-beginning 2) ;; @+I+2 (org-table--rematch-and-replace 2 (eq dir 'up) t)) ((match-beginning 3) ;; @1 (org-table--rematch-and-replace 3 (eq dir 'up) t)) ((match-beginning 1) ;; @_ (goto-char (1+ (match-beginning 1))) (insert (my-org-table-fedit-current-line-str dir))) (t (when (or (match-beginning 4) (match-beginning 6)) ;; _$ (goto-char (or (match-beginning 4) (match-beginning 6)))) (insert "@" (my-org-table-fedit-current-line-str dir))))) ;; Left or Right (t (cond ((match-beginning 5) ;; @ $1 (org-table--rematch-and-replace 5 (eq dir 'left))) ((match-beginning 4) ;; @ $ (goto-char (1+ (match-beginning 4))) (insert (my-org-table-fedit-current-column-str dir))) ((match-beginning 7) ;; $1 (org-table--rematch-and-replace 7 (eq dir 'left))) ((match-beginning 6) ;; $_ (goto-char (1+ (match-beginning 6))) (insert (my-org-table-fedit-current-column-str dir))) (t (when (match-end 1) ;; @_ (goto-char (match-end 1))) (insert "$" (my-org-table-fedit-current-column-str dir))))))) ;; Add a new reference (t (if (memq dir '(up down)) (insert "@" (my-org-table-fedit-current-line-str dir)) (insert "$" (my-org-table-fedit-current-column-str dir)))))) (advice-add #'org-table-fedit-shift-reference :override #'my-org-table-fedit-shift-reference) (defun my-org-table-fedit-current-column-str (&optional dir) ;; (pcase dir ('left "-1") ('right "+1") (_ "+0")) (number-to-string (+ (with-current-buffer (marker-buffer org-pos) (org-table-current-column)) (pcase dir ('left -1) ('right 1) (_ 0))))) (defun my-org-table-fedit-current-line-str (&optional dir) (pcase dir ('up "-1") ('down "+1") (_ "+0")) ;; 行番号を絶対指定にしたい場合は↓を使う ;; (number-to-string ;; (+ ;; (with-current-buffer (marker-buffer org-pos) (org-table-current-line)) ;; (pcase dir ('up -1) ('down 1) (_ 0)))) ) ;; `org-table-shift-refpart'を改善する。 ;; - @>や$<<への対応 (defun my-org-table-shift-refpart:around (old-fun ref &optional decr hline) (if (and (stringp ref) (> (length ref) 0) (memq (aref ref 0) '(?< ?>))) (let* ((ch (aref ref 0)) (delta (if (xor decr (eq ch ?>)) -1 1)) (new-len (max 1 (+ (length ref) delta)))) (make-string new-len ch)) (funcall old-fun ref decr hline))) (advice-add #'org-table-shift-refpart :around #'my-org-table-shift-refpart:around)
org-table-fedit-shift-referenceは丸丸置き換えてしまうことにしました。
ハイライトが@>や$<といった形式に対応していない問題が残っていますが、org-table-show-referenceは手を入れづらい構造なので諦めました。
参照先変更時の不要なスクロールを抑制する
Shift+矢印キーで参照先を変更したとき、表の先頭がウィンドウの先頭に来るようにスクロールされてしまいます。それが良い場合もあるのでしょうが、気に入らないので不要なスクロールはしないようにします。
;; `org-table-show-reference'を改善する。 ;; - 不要なスクロールをしない (defun my-org-table-show-reference:around (old-fun &rest args) (cl-letf* ((old-set-window-start (symbol-function 'set-window-start)) ((symbol-function 'set-window-start) (lambda (window pos &rest args) (unless (pos-visible-in-window-p pos window) (apply old-set-window-start window pos args))))) (apply old-fun args))) (advice-add #'org-table-show-reference :around #'my-org-table-show-reference:around)
長い関数の最後あたり(org-table-show-referenceのset-window-startを呼び出しているあたり)を修正しなければならないのでかなり無理矢理です。
完全に何もしないようにしてしまっても良いかもしれません。
結果
書いたコードはGistにmy-org-table.elというファイルで置いておきます。これまでにorg-table.elに対して行った他の全ての改善も一緒に入れておきました。
init.elで次のようにすれば修正が適用されると思います。
(with-eval-after-load "org" (require 'my-org-table))
本当はこういうのは本家にパッチでも送れば良いんでしょうけどやりとりが面倒ですしね~(みんなそうだからいつまで経っても大本が直らない説)