Emacs 30からmodifier-bar-modeが追加されました。これは修飾キーの入力ボタンを表示するグローバルマイナーモードです。
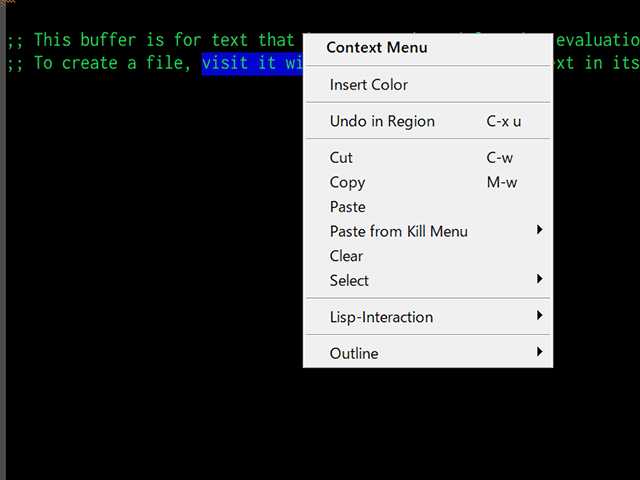
M-x modifier-bar-modeとタイプすると次のようなツールバーが表示されます(ツールバーの一種なので、先にtool-bar-mode等でツールバー自体も表示しておく必要があると思います)。
図1: modifier-bar-mode
見ての通りボタンはCtrl、Shift、Meta、Alt、Super、Hyperの六つです。例えばC-M-iと入力したければCtrlボタンとMetaボタンを押してからiを押せば良いということになります。
もちろん普通のキーボードを使っていれば必要になることはほとんど無いと思いますが、AndroidでCtrl等が無いソフトキーボードを使っているときは重宝するでしょう。PCでも左手でポテチをつまみながら右手でマウスを握りリラックスしながらポチポチやってるときには便利かもしれません。
とは言え、実際Androidスマホでこれを使ってみたところ、案外痒いところに手が届かないと言いましょうか、これじゃ全然足りないよ! という気持ちになりました。
スマホで使用するソフトキーボードというのは本当にキーが小さくて押しづらいです。Hacker's Keyboardはちゃんと修飾キーも押せるソフトキーボードですが、Ctrl、xと押すだけでもキーが小さすぎて神経を使います。1キーでC-xまで入力させてほしいのです。他にも1ボタンで入力できれば便利なキーは沢山あります。
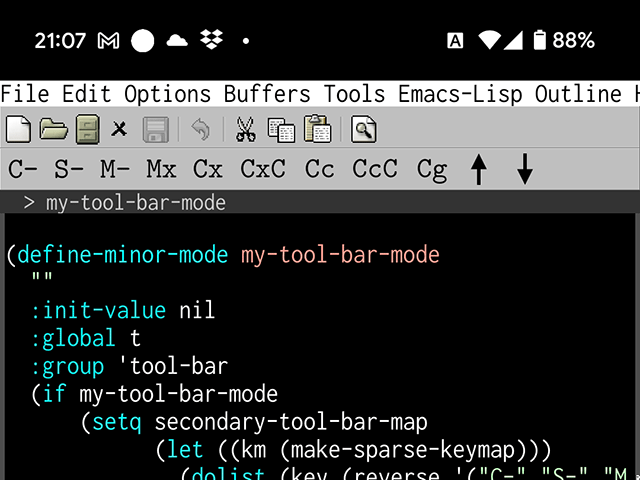
そこで、このmodifier-bar-modeを元に自分なりのキー入力補助ツールバーを作ってみました。それを有効にすると次のようになります。
図2: my-tool-bar-mode
修飾キーは C- S- M- の三つで簡素に表示します。
A- s- H- はスペースの都合で諦めました。どうせ使わないでしょう。C-x C-c というプレフィックスはやはり1ボタンで入力したいところ。追加で C-x や C-c の後にさらに C- を続けるパターンもボタン化しました。
M-x はメニューのEdit→Execute Commandでも呼び出せますが、やはり1ボタンにしたいです。C-g もなんだかんだ言って欲しくなります。矢印キーの上と下は普通の日本語IMEを使っているときに重宝します。GboardにせよATOKにせよ左右キーはあっても上下キーは無いからです。
というわけで以下ソースコード。
(require 'tool-bar )
(defconst my-tool-bar-svg-alist
'(("C-" . "<g><path d=\"M9.0 5.2C9.0 5.0 9.0 4.6 8.5 4.6 8.2 4.6 8.1 4.7 8.0 4.8 8.0 4.9 8.0 4.9 7.8 5.4 7.2 4.9 6.5 4.6 5.6 4.6 3.5 4.6 1.6 6.8 1.6 9.8 1.6 12.9 3.5 15.1 5.6 15.1 7.6 15.1 9.0 13.6 9.0 12.1 9.0 11.6 8.6 11.6 8.4 11.6 8.3 11.6 7.9 11.6 7.9 12.1 7.7 13.7 6.4 14.1 5.7 14.1 4.2 14.1 2.8 12.3 2.8 9.8 2.8 7.3 4.2 5.6 5.7 5.6 6.7 5.6 7.6 6.3 7.8 7.7 7.9 8.0 7.9 8.2 8.4 8.2 9.0 8.2 9.0 7.9 9.0 7.6Z\" /><path d=\"M16.7 10.4C16.9 10.4 17.5 10.4 17.5 9.8S16.9 9.2 16.7 9.2H11.4C11.2 9.2 10.6 9.2 10.6 9.8 10.6 10.4 11.2 10.4 11.4 10.4Z\" /></g>" )
("S-" . "<g><path d=\"M5.9 10.3C6.3 10.4 7.7 10.8 7.7 12.2 7.7 13.1 7.0 14.0 5.7 14.0 5.2 14.0 4.4 14.0 3.7 13.5 3.0 13.1 3.0 12.4 3.0 12.1 2.9 11.8 2.9 11.5 2.4 11.5 1.8 11.5 1.8 11.9 1.8 12.2V14.4C1.8 14.6 1.8 15.1 2.3 15.1 2.7 15.1 2.8 14.8 2.9 14.3 3.6 14.8 4.6 15.1 5.7 15.1 7.6 15.1 8.8 13.6 8.8 12.1 8.8 11.1 8.2 10.4 8.0 10.1 7.3 9.5 6.9 9.4 5.6 9.1L4.2 8.8C3.5 8.6 2.9 8.0 2.9 7.2 2.9 6.3 3.7 5.5 4.9 5.5 6.9 5.5 7.1 7.1 7.2 7.6 7.3 8.0 7.4 8.1 7.8 8.1 8.4 8.1 8.4 7.7 8.4 7.4V5.2C8.4 4.9 8.4 4.5 7.9 4.5 7.5 4.5 7.4 4.8 7.2 5.3 6.6 4.7 5.7 4.5 4.9 4.5 3.1 4.5 1.8 5.8 1.8 7.3 1.8 8.4 2.6 9.5 4.0 9.9 4.0 9.9 5.6 10.3 5.9 10.3Z\" /><path d=\"M16.7 10.4C16.9 10.4 17.5 10.4 17.5 9.8S16.9 9.2 16.7 9.2H11.4C11.2 9.2 10.6 9.2 10.6 9.8S11.2 10.4 11.4 10.4Z\" /></g>" )
("M-" . "<g><path d=\"M5.8 8.7C5.6 9.3 5.4 9.8 5.3 10.3H5.3C5.1 9.5 3.7 5.2 3.6 5.1 3.5 4.7 3.1 4.7 2.8 4.7H1.9C1.6 4.7 1.2 4.7 1.2 5.2 1.2 5.7 1.6 5.7 2.1 5.7V13.8C1.6 13.8 1.2 13.8 1.2 14.3 1.2 14.8 1.6 14.8 1.9 14.8H3.3C3.5 14.8 3.9 14.8 3.9 14.3 3.9 13.8 3.6 13.8 3.0 13.8V5.9H3.1C3.2 6.7 4.3 9.9 4.4 10.1 4.5 10.5 4.7 11.1 4.8 11.2 4.9 11.3 5.1 11.5 5.3 11.5 5.5 11.5 5.8 11.3 5.9 11.1 5.9 11.0 7.4 6.8 7.6 5.9H7.6V13.8C7.0 13.8 6.7 13.8 6.7 14.3 6.7 14.8 7.1 14.8 7.4 14.8H8.7C9.0 14.8 9.4 14.8 9.4 14.3 9.4 13.8 9.0 13.8 8.5 13.8V5.7C9.0 5.7 9.4 5.7 9.4 5.2 9.4 4.7 9.0 4.7 8.7 4.7H7.8C7.1 4.7 7.0 4.9 6.9 5.3Z\" /><path d=\"M16.7 10.3C16.9 10.3 17.5 10.3 17.5 9.8S16.9 9.2 16.7 9.2H11.4C11.2 9.2 10.6 9.2 10.6 9.8S11.2 10.3 11.4 10.3Z\" /></g>" )
("A-" . "<g><path d=\"M6.2 5.1C6.1 4.5 5.8 4.4 5.3 4.4 4.8 4.4 4.6 4.4 4.4 5.1L2.4 13.8C2.2 13.8 1.8 13.8 1.7 13.8 1.5 13.9 1.4 14.1 1.4 14.3 1.4 14.8 1.8 14.8 2.1 14.8H3.8C4.1 14.8 4.5 14.8 4.5 14.3 4.5 13.8 4.2 13.8 3.6 13.8L4.0 12.1H6.7L7.0 13.8C6.4 13.8 6.1 13.8 6.1 14.3 6.1 14.8 6.5 14.8 6.8 14.8H8.5C8.8 14.8 9.2 14.8 9.2 14.3 9.2 14.1 9.1 13.9 8.9 13.8 8.8 13.8 8.5 13.8 8.2 13.8ZM5.3 5.8H5.3L6.4 11.1H4.2Z\" /><path d=\"M16.7 10.3C16.9 10.3 17.5 10.3 17.5 9.7S16.9 9.1 16.7 9.1H11.4C11.2 9.1 10.6 9.1 10.6 9.7S11.2 10.3 11.4 10.3Z\" /></g>" )
("s-" . "<g><path d=\"M5.9 10.5C5.5 10.5 5.2 10.4 4.8 10.3 4.3 10.3 3.2 10.1 3.2 9.4 3.2 9.0 3.7 8.5 5.3 8.5 6.7 8.5 6.9 9.0 6.9 9.4 7.0 9.7 7.0 10.0 7.5 10.0 8.1 10.0 8.1 9.6 8.1 9.3V8.1C8.1 7.9 8.1 7.5 7.6 7.5 7.2 7.5 7.1 7.7 7.1 7.8 6.4 7.5 5.6 7.5 5.3 7.5 2.5 7.5 2.1 8.8 2.1 9.4 2.1 10.9 3.9 11.2 5.4 11.5 6.2 11.6 7.6 11.8 7.6 12.7 7.6 13.3 7.0 13.9 5.4 13.9 4.7 13.9 3.7 13.7 3.3 12.4 3.2 12.1 3.2 11.9 2.7 11.9 2.1 11.9 2.1 12.2 2.1 12.6V14.2C2.1 14.5 2.1 14.9 2.6 14.9 2.8 14.9 3.1 14.9 3.3 14.2 4.1 14.8 5.0 14.9 5.4 14.9 8.1 14.9 8.6 13.5 8.6 12.7 8.6 11.0 6.4 10.6 5.9 10.5Z\" /><path d=\"M16.7 10.3C16.9 10.3 17.5 10.3 17.5 9.7S16.9 9.1 16.7 9.1H11.4C11.2 9.1 10.6 9.1 10.6 9.7S11.2 10.3 11.4 10.3Z\" /></g>" )
("H-" . "<g><path d=\"M8.2 5.6H8.6C8.9 5.6 9.3 5.6 9.3 5.1 9.3 4.6 8.9 4.6 8.6 4.6H6.7C6.4 4.6 6.0 4.6 6.0 5.1 6.0 5.6 6.4 5.6 6.7 5.6H7.1V9.0H3.5V5.6H4.0C4.2 5.6 4.6 5.6 4.6 5.1 4.6 4.6 4.2 4.6 4.0 4.6H2.0C1.7 4.6 1.3 4.6 1.3 5.1 1.3 5.6 1.7 5.6 2.0 5.6H2.4V13.7H2.0C1.7 13.7 1.3 13.7 1.3 14.2 1.3 14.7 1.7 14.7 2.0 14.7H4.0C4.2 14.7 4.6 14.7 4.6 14.2 4.6 13.7 4.2 13.7 4.0 13.7H3.5V10.0H7.1V13.7H6.7C6.4 13.7 6.0 13.7 6.0 14.2 6.0 14.7 6.4 14.7 6.7 14.7H8.6C8.9 14.7 9.3 14.7 9.3 14.2 9.3 13.7 8.9 13.7 8.6 13.7H8.2Z\" /><path d=\"M16.7 10.2C16.9 10.2 17.5 10.2 17.5 9.6S16.9 9.1 16.7 9.1H11.4C11.2 9.1 10.6 9.1 10.6 9.6S11.2 10.2 11.4 10.2Z\" /></g>" )
("Mx" . "<g><path d=\"M5.8 8.6C5.6 9.2 5.4 9.6 5.3 10.1H5.3C5.1 9.3 3.7 5.0 3.6 4.9 3.5 4.5 3.1 4.5 2.8 4.5H1.9C1.6 4.5 1.2 4.5 1.2 5.0 1.2 5.6 1.6 5.6 2.1 5.6V13.7C1.6 13.7 1.2 13.7 1.2 14.2 1.2 14.7 1.6 14.7 1.9 14.7H3.3C3.5 14.7 3.9 14.7 3.9 14.2 3.9 13.7 3.6 13.7 3.0 13.7V5.8H3.1C3.2 6.5 4.3 9.7 4.4 9.9 4.5 10.3 4.7 10.9 4.8 11.1 4.9 11.2 5.1 11.3 5.3 11.3 5.5 11.3 5.8 11.2 5.9 10.9 5.9 10.8 7.4 6.6 7.6 5.8H7.6V13.7C7.0 13.7 6.7 13.7 6.7 14.2 6.7 14.7 7.1 14.7 7.4 14.7H8.7C9.0 14.7 9.4 14.7 9.4 14.2 9.4 13.7 9.0 13.7 8.5 13.7V5.6C9.0 5.6 9.4 5.6 9.4 5.0 9.4 4.5 9.0 4.5 8.7 4.5H7.8C7.1 4.5 7.0 4.8 6.9 5.2Z\" /><path d=\"M14.5 11.0 16.4 8.6H17.0C17.3 8.6 17.7 8.6 17.7 8.1 17.7 7.5 17.3 7.5 17.0 7.5H15.1C14.8 7.5 14.4 7.5 14.4 8.0 14.4 8.6 14.8 8.6 15.2 8.6L14.0 10.2 12.7 8.6C13.2 8.6 13.5 8.6 13.5 8.0 13.5 7.5 13.1 7.5 12.9 7.5H10.9C10.7 7.5 10.2 7.5 10.2 8.1 10.2 8.6 10.7 8.6 10.9 8.6H11.6L13.5 11.0 11.5 13.7H10.8C10.6 13.7 10.1 13.7 10.1 14.2 10.1 14.7 10.6 14.7 10.8 14.7H12.8C13.0 14.7 13.4 14.7 13.4 14.2 13.4 13.7 13.1 13.7 12.6 13.7L14.0 11.6 15.5 13.7C15.0 13.7 14.6 13.7 14.6 14.2 14.6 14.7 15.1 14.7 15.3 14.7H17.3C17.5 14.7 17.9 14.7 17.9 14.2 17.9 13.7 17.5 13.7 17.3 13.7H16.6Z\" /></g>" )
("Cx" . "<g><path d=\"M9.0 5.0C9.0 4.7 9.0 4.3 8.5 4.3 8.2 4.3 8.1 4.5 8.0 4.6 8.0 4.7 8.0 4.7 7.8 5.1 7.2 4.7 6.5 4.3 5.6 4.3 3.5 4.3 1.6 6.6 1.6 9.6 1.6 12.6 3.5 14.9 5.6 14.9 7.6 14.9 9.0 13.4 9.0 11.9 9.0 11.3 8.6 11.3 8.4 11.3 8.3 11.3 7.9 11.3 7.9 11.8 7.7 13.4 6.4 13.8 5.7 13.8 4.2 13.8 2.8 12.1 2.8 9.6 2.8 7.1 4.2 5.3 5.7 5.3 6.7 5.3 7.6 6.1 7.8 7.5 7.9 7.7 7.9 8.0 8.4 8.0 9.0 8.0 9.0 7.7 9.0 7.3Z\" /><path d=\"M14.5 11.0 16.4 8.5H17.0C17.3 8.5 17.7 8.5 17.7 8.0 17.7 7.5 17.3 7.5 17.0 7.5H15.1C14.8 7.5 14.4 7.5 14.4 8.0 14.4 8.5 14.8 8.5 15.2 8.5L14.0 10.2 12.7 8.5C13.2 8.5 13.5 8.5 13.5 8.0 13.5 7.5 13.1 7.5 12.9 7.5H10.9C10.7 7.5 10.2 7.5 10.2 8.0 10.2 8.5 10.7 8.5 10.9 8.5H11.6L13.5 11.0 11.5 13.7H10.8C10.6 13.7 10.1 13.7 10.1 14.2 10.1 14.7 10.6 14.7 10.8 14.7H12.8C13.0 14.7 13.4 14.7 13.4 14.2 13.4 13.7 13.1 13.7 12.6 13.7L14.0 11.6 15.5 13.7C15.0 13.7 14.6 13.7 14.6 14.2 14.6 14.7 15.1 14.7 15.3 14.7H17.3C17.5 14.7 17.9 14.7 17.9 14.2 17.9 13.7 17.5 13.7 17.3 13.7H16.6Z\" /></g>" )
("CxC" . "<g><path d=\"M9.0 5.0C9.0 4.7 9.0 4.3 8.5 4.3 8.2 4.3 8.1 4.5 8.0 4.6 8.0 4.6 8.0 4.7 7.8 5.1 7.2 4.6 6.5 4.3 5.6 4.3 3.5 4.3 1.6 6.5 1.6 9.5 1.6 12.6 3.5 14.8 5.6 14.8 7.6 14.8 9.0 13.3 9.0 11.8 9.0 11.3 8.6 11.3 8.4 11.3 8.3 11.3 7.9 11.3 7.9 11.8 7.7 13.4 6.4 13.8 5.7 13.8 4.2 13.8 2.8 12.0 2.8 9.5 2.8 7.1 4.2 5.3 5.7 5.3 6.7 5.3 7.6 6.1 7.8 7.4 7.9 7.7 7.9 8.0 8.4 8.0 9.0 8.0 9.0 7.6 9.0 7.3Z\" /><path d=\"M14.5 10.9 16.4 8.5H17.0C17.3 8.5 17.7 8.5 17.7 8.0 17.7 7.5 17.3 7.5 17.0 7.5H15.1C14.8 7.5 14.4 7.5 14.4 8.0 14.4 8.5 14.8 8.5 15.2 8.5L14.0 10.2 12.7 8.5C13.2 8.5 13.5 8.5 13.5 8.0 13.5 7.5 13.1 7.5 12.9 7.5H10.9C10.7 7.5 10.2 7.5 10.2 8.0 10.2 8.5 10.7 8.5 10.9 8.5H11.6L13.5 10.9 11.5 13.6H10.8C10.6 13.6 10.1 13.6 10.1 14.1 10.1 14.6 10.6 14.6 10.8 14.6H12.8C13.0 14.6 13.4 14.6 13.4 14.1 13.4 13.6 13.1 13.6 12.6 13.6L14.0 11.6 15.5 13.6C15.0 13.6 14.6 13.6 14.6 14.1 14.6 14.6 15.1 14.6 15.3 14.6H17.3C17.5 14.6 17.9 14.6 17.9 14.1 17.9 13.6 17.5 13.6 17.3 13.6H16.6Z\" /><path d=\"M26.5 5.0C26.5 4.7 26.5 4.3 26.0 4.3 25.7 4.3 25.6 4.5 25.5 4.6 25.5 4.6 25.5 4.7 25.3 5.1 24.7 4.6 23.9 4.3 23.1 4.3 20.9 4.3 19.1 6.5 19.1 9.5 19.1 12.6 20.9 14.8 23.1 14.8 25.0 14.8 26.5 13.3 26.5 11.8 26.5 11.3 26.1 11.3 25.9 11.3 25.7 11.3 25.4 11.3 25.3 11.8 25.2 13.4 23.9 13.8 23.2 13.8 21.7 13.8 20.2 12.0 20.2 9.5 20.2 7.1 21.7 5.3 23.2 5.3 24.2 5.3 25.1 6.1 25.3 7.4 25.4 7.7 25.4 8.0 25.9 8.0 26.5 8.0 26.5 7.6 26.5 7.3Z\" /></g>" )
("Cc" . "<g><path d=\"M9.0 4.9C9.0 4.7 9.0 4.3 8.5 4.3 8.2 4.3 8.1 4.4 8.0 4.5 8.0 4.6 8.0 4.6 7.8 5.1 7.2 4.6 6.5 4.3 5.6 4.3 3.5 4.3 1.6 6.5 1.6 9.5 1.6 12.6 3.5 14.8 5.6 14.8 7.6 14.8 9.0 13.3 9.0 11.8 9.0 11.3 8.6 11.3 8.4 11.3 8.3 11.3 7.9 11.3 7.9 11.7 7.7 13.4 6.4 13.8 5.7 13.8 4.2 13.8 2.8 12.0 2.8 9.5 2.8 7.0 4.2 5.3 5.7 5.3 6.7 5.3 7.6 6.0 7.8 7.4 7.9 7.7 7.9 7.9 8.4 7.9 9.0 7.9 9.0 7.6 9.0 7.2Z\" /><path d=\"M17.4 12.8C17.4 12.3 17.0 12.3 16.9 12.3 16.6 12.3 16.4 12.4 16.3 12.7 16.2 12.9 15.9 13.7 14.7 13.7 13.2 13.7 12.0 12.5 12.0 11.0 12.0 10.2 12.5 8.3 14.8 8.3 15.1 8.3 15.8 8.3 15.8 8.4 15.8 9.0 16.1 9.3 16.5 9.3S17.2 9.0 17.2 8.5C17.2 7.3 15.5 7.3 14.8 7.3 11.9 7.3 10.9 9.5 10.9 11.0 10.9 13.0 12.5 14.7 14.6 14.7 16.9 14.7 17.4 13.1 17.4 12.8Z\" /></g>" )
("CcC" . "<g><path d=\"M9.0 4.9C9.0 4.6 9.0 4.2 8.5 4.2 8.2 4.2 8.1 4.4 8.0 4.5 8.0 4.6 8.0 4.6 7.8 5.0 7.2 4.6 6.5 4.2 5.6 4.2 3.5 4.2 1.6 6.4 1.6 9.5 1.6 12.5 3.5 14.7 5.6 14.7 7.6 14.7 9.0 13.3 9.0 11.8 9.0 11.2 8.6 11.2 8.4 11.2 8.3 11.2 7.9 11.2 7.9 11.7 7.7 13.3 6.4 13.7 5.7 13.7 4.2 13.7 2.8 12.0 2.8 9.5 2.8 7.0 4.2 5.2 5.7 5.2 6.7 5.2 7.6 6.0 7.8 7.3 7.9 7.6 7.9 7.9 8.4 7.9 9.0 7.9 9.0 7.5 9.0 7.2Z\" /><path d=\"M17.4 12.8C17.4 12.3 17.0 12.3 16.9 12.3 16.6 12.3 16.4 12.3 16.3 12.7 16.2 12.9 15.9 13.7 14.7 13.7 13.2 13.7 12.0 12.5 12.0 11.0 12.0 10.2 12.5 8.3 14.8 8.3 15.1 8.3 15.8 8.3 15.8 8.4 15.8 9.0 16.1 9.2 16.5 9.2S17.2 8.9 17.2 8.5C17.2 7.2 15.5 7.2 14.8 7.2 11.9 7.2 10.9 9.5 10.9 11.0 10.9 13.0 12.5 14.7 14.6 14.7 16.9 14.7 17.4 13.0 17.4 12.8Z\" /><path d=\"M26.5 4.9C26.5 4.6 26.5 4.2 26.0 4.2 25.7 4.2 25.6 4.4 25.5 4.5 25.5 4.6 25.5 4.6 25.3 5.0 24.7 4.6 23.9 4.2 23.1 4.2 20.9 4.2 19.1 6.4 19.1 9.5 19.1 12.5 20.9 14.7 23.1 14.7 25.0 14.7 26.5 13.3 26.5 11.8 26.5 11.2 26.1 11.2 25.9 11.2 25.7 11.2 25.4 11.2 25.3 11.7 25.2 13.3 23.9 13.7 23.2 13.7 21.7 13.7 20.2 12.0 20.2 9.5 20.2 7.0 21.7 5.2 23.2 5.2 24.2 5.2 25.1 6.0 25.3 7.3 25.4 7.6 25.4 7.9 25.9 7.9 26.5 7.9 26.5 7.5 26.5 7.2Z\" /></g>" )
("Cg" . "<g><path d=\"M9.0 4.9C9.0 4.6 9.0 4.2 8.5 4.2 8.2 4.2 8.1 4.3 8.0 4.5 8.0 4.5 8.0 4.6 7.8 5.0 7.2 4.5 6.5 4.2 5.6 4.2 3.5 4.2 1.6 6.4 1.6 9.4 1.6 12.5 3.5 14.7 5.6 14.7 7.6 14.7 9.0 13.2 9.0 11.7 9.0 11.2 8.6 11.2 8.4 11.2 8.3 11.2 7.9 11.2 7.9 11.7 7.7 13.3 6.4 13.7 5.7 13.7 4.2 13.7 2.8 11.9 2.8 9.4 2.8 7.0 4.2 5.2 5.7 5.2 6.7 5.2 7.6 6.0 7.8 7.3 7.9 7.6 7.9 7.9 8.4 7.9 9.0 7.9 9.0 7.5 9.0 7.2Z\" /><path d=\"M13.6 11.6C12.7 11.6 12.0 10.8 12.0 9.9 12.0 9.0 12.7 8.3 13.6 8.3 14.5 8.3 15.2 9.0 15.2 9.9 15.2 10.9 14.4 11.6 13.6 11.6ZM12.1 12.2C12.1 12.2 12.7 12.6 13.6 12.6 15.1 12.6 16.3 11.4 16.3 9.9 16.3 9.4 16.2 8.9 15.9 8.5 16.2 8.3 16.6 8.2 16.8 8.2 16.9 8.6 17.3 8.8 17.5 8.8 17.8 8.8 18.2 8.6 18.2 8.1 18.2 7.7 17.8 7.2 16.9 7.2 16.8 7.2 15.9 7.2 15.2 7.8 14.9 7.6 14.3 7.3 13.6 7.3 12.0 7.3 10.8 8.5 10.8 9.9 10.8 10.6 11.1 11.2 11.3 11.5 11.2 11.8 11.0 12.1 11.0 12.6 11.0 13.2 11.2 13.6 11.4 13.8 10.2 14.6 10.2 15.7 10.2 15.9 10.2 17.3 11.9 18.3 14.0 18.3 16.2 18.3 17.9 17.3 17.9 15.9 17.9 15.3 17.6 14.4 16.8 14.0 16.6 13.9 15.9 13.5 14.4 13.5H13.2C13.1 13.5 12.8 13.5 12.7 13.5 12.5 13.5 12.4 13.5 12.2 13.3 12.0 13.0 12.0 12.7 12.0 12.7 12.0 12.6 12.0 12.4 12.1 12.2ZM14.0 17.3C12.4 17.3 11.1 16.6 11.1 15.9 11.1 15.6 11.3 15.1 11.8 14.7 12.2 14.5 12.4 14.5 13.6 14.5 15.1 14.5 17.0 14.5 17.0 15.9 17.0 16.6 15.7 17.3 14.0 17.3Z\" /></g>" )
("Up" . "<path d=\"M10 1 5.5 10H9V19H11V10H14.5Z\" />" )
("Do" . "<path d=\"M10 19 5.5 10H9V1H11V10H14.5Z\" />" )))
(defun my-tool-bar-image (text)
"TEXTに対応する画像(Image Descriptor)を返す。"
(when-let* ((svg (alist-get text my-tool-bar-svg-alist nil nil #'equal)))
(list 'image
:type 'svg :data
(concat
(format "<svg xmlns=\"http://www.w3.org/2000/svg\" width=\"%s\" height=\"%s\" fill=\"#000\" viewBox=\"0 0 %s %s\" >"
(* (length text) 16) 28
(* (length text) 10) 20)
svg "</svg>" )
:scale 'default)))
(define-minor-mode my-tool-bar-mode
"私だけの特別なツールバー。"
:init-value nil
:global t
:group 'tool-bar
(if my-tool-bar-mode
(setq secondary-tool-bar-map
(let ((km (make-sparse-keymap)))
(dolist (key (reverse '("C-" "S-" "M-"
"Mx" "Cx" "CxC" "Cc" "CcC"
"Cg" "Up" "Do" )))
(my-tool-bar-add-prefix-item km key))
km))
(setq secondary-tool-bar-map nil))
(force-mode-line-update t))
(defun my-tool-bar-decode-C- (_prompt)
(modifier-bar-button '(control)))
(defun my-tool-bar-decode-S- (_prompt)
(modifier-bar-button '(shift)))
(defun my-tool-bar-decode-M- (_prompt)
(modifier-bar-button '(meta)))
(defun my-tool-bar-decode-A- (_prompt)
(modifier-bar-button '(alt)))
(defun my-tool-bar-decode-s- (_prompt)
(modifier-bar-button '(super)))
(defun my-tool-bar-decode-H- (_prompt)
(modifier-bar-button '(hyper)))
(defun my-tool-bar-decode-Mx (_prompt)
(kbd "M-x" ))
(defun my-tool-bar-decode-Cx (_prompt)
(kbd "C-x" ))
(defun my-tool-bar-decode-CxC (_prompt)
(vconcat
(kbd "C-x" )
(modifier-bar-button '(control))))
(defun my-tool-bar-decode-Cc (_prompt)
(kbd "C-c" ))
(defun my-tool-bar-decode-CcC (_prompt)
(vconcat
(kbd "C-c" )
(modifier-bar-button '(control))))
(defun my-tool-bar-decode-Cg (_prompt)
(kbd "C-g" ))
(defun my-tool-bar-decode-Up (_prompt)
(kbd "<up>" ))
(defun my-tool-bar-decode-Do (_prompt)
(kbd "<down>" ))
(defun my-tool-bar-add-prefix-item (km key-str)
(let* ((modifier (alist-get key-str
'(("C-" . control) ("S-" . shift)
("M-" . meta) ("A-" . alt)
("s-" . super) ("H-" . hyper))
nil nil #'equal))
(key-sym (or modifier
(intern key-str)))
(decode-fun (intern (format "my-tool-bar-decode-%s" key-str))))
(define-key km (vector key-sym)
(list
'menu-item key-str #'ignore
:image (my-tool-bar-image key-str)
:help (if modifier
(format "Add %s to the following event" key-str)
key-str)
:enable (if modifier
`(modifier-bar-available-p (quote ,modifier))
t)))
(define-key input-decode-map (vector 'tool-bar key-sym) decode-fun)))
実装の一部は modifier-bar-mode のコードを呼び出しています。
入力イベントに修飾キーを付加するのにinput-decode-map modifier-bar-button
ツールバーへのボタンの表示はsecondary-tool-bar-map
ただし、項目文字列が表示されることは無く、代わりに画像を指定してやる必要があります。modifier-bar-mode image-load-path
わざわざ画像を用意するのは億劫だなと思いましたが、試してみたところSVG画像でも表示できるようでした(WindowsとAndroidの両方で確認)。
しかしここで残念なお知らせが。
現在のAndroid版EmacsはSVGでtext要素が表示できません。
最初はフォントが見つけられないだけかなとも思ったのですが、 java/INSTALL の中に次のような記述を見つけました。
LIBRSVG
Librsvg 2.40.21, the final release in the librsvg 2.40.x series, the
last to be implemented in C, is provided as:
librsvg-2.40.21-emacs.tar.gz
and has been lightly edited for compatibility with environments where
Pango cannot provide fonts, with the obvious caveat that text cannot be
displayed with the resulting librsvg binary. Among numerous
dependencies are PCRE, and:
libiconv-1.17-emacs.tar.gz
libffi-3.4.5-emacs.tar.gz
pango-1.38.1-emacs.tar.gz
glib-2.33.14-emacs.tar.gz
libcroco-0.6.13-emacs.tar.gz
pixman-0.38.4-emacs.tar.gz
libxml2-2.12.4-emacs.tar.gz
gdk-pixbuf-2.22.1-emacs.tar.gz
giflib-5.2.1-emacs.tar.gz
libjpeg-turbo-3.0.2-emacs.tar.gz
libpng-1.6.41-emacs.tar.gz
tiff-4.5.1-emacs.tar.gz
cairo-1.16.0-emacs.tar.gz
which must be individually unpacked and their contents provided on the
command line, as with other dependencies. They will introduce
approximately 8 MiB's worth of shared libraries into the finished
application package. It is unlikely that later releases of librsvg will
ever be ported, as they have migrated to a different implementation
language.
No effort has been expended on providing the latest and greatest of
these dependencies either; rather, the versions chosen are often the
earliest versions required by their dependents, these being the smaller
of all available versions, and generally more straightforward to port.
よく分かりませんが、テキストが表示できないのは仕様ということなのでしょうか? librsvg-2.40自体もかなり古いものなのでサポートしていないSVGの機能やバグが沢山あるはずです。 残念ですがとりあえずSVGでtext要素を使うのは諦めるよりありません。
というわけで上のソースコードにはLaTeXで生成した文字のパスデータが長々と並んでいるわけです。