先日からEmacsの中で動く作図ツールを作っています。
https://github.com/misohena/el-easydraw
その一環として今日はカラーピッカーを作りました。この手のソフトには必ずあるアレです。
Emacs上での先行事例はいくつかあるようでしたがSVGでの実装は見当たりませんでしたし、まぁ、自分で作りたいじゃないですか。こういうの作るの楽しいですし。
というわけで出来たのがこちら。
https://github.com/misohena/el-easydraw/blob/master/edraw-color-picker.el
一応ライブラリとして他で使い回すことを考えています。
応用としてとりあえず作ったコマンドがいくつか。
edraw-color-picker-read-colorはread-colorの代わりを意識して作った色入力コマンドです。ミニバッファ内にカラーピッカーを配置してみました。文字からでもカラーピッカーからでも色を選択できます。
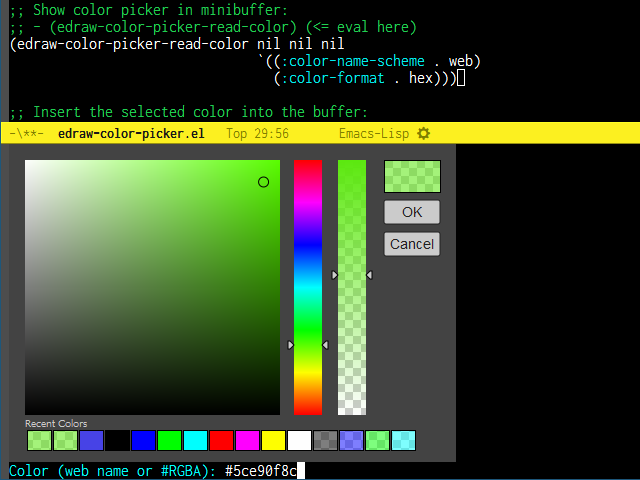
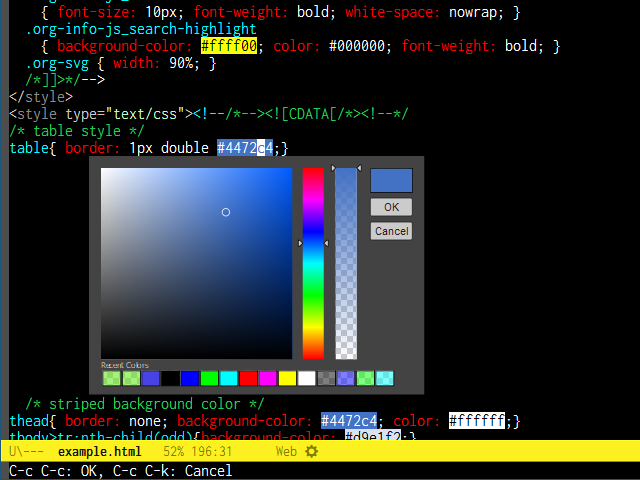
edraw-color-picker-insert-colorは選択した色をそのままバッファに挿入するコマンドです。またedraw-color-picker-replace-color-at-pointは現在のポイントの位置にある色表記を読み取ってカラーピッカーで選択した色に置き換えるコマンドです。これらはバッファ内にインラインでカラーピッカーが表示されます。
SVGは本当に簡単でこういう絵を出すのはサクッとすぐに出来ます。いや、本当は少し調査が必要だったのが二点。meshGradientの対応状況と色相バーの仕様です。こういう二次元のグラデーションで連想するのがメッシュ状の図形(いわゆるポリゴンの組み合わせ)で頂点に色を設定する仕組みです。3Dグラフィックスではおなじみですよね。SVGにも似たような仕組みがあったようなと調べてみたのですが、残念ながらEmacs(というかlibrsvg)では対応していないようですね(そもそもmeshGradient自体がSVG2から先送りされてたんですね)。幸い二枚のグラデーションを重ねれば良いとすぐに気がつけました。もう一点の色相バーですが、これ6色(赤、黄、緑、水、青、紫)を均等に並べて線形補間すればいいだけみたいですね。というわけでそれさえ分かればこういうカラーピッカーの絵自体はすぐに作れました。
画像内の各パーツは「領域」というオブジェクトで構成されています。指定に基づいて「領域」をレイアウト処理することで、いくらか柔軟に構成要素を増やしたり減らしたりできるようになっています。
領域にマウスイベントを配信(ディスパッチ)する仕組みを作り、それに反応して各部が動くようにしていきます。マウスイベントを受けて関連付けられた値が変わり、値の変更が通知されて表示が変わります。
各領域で選択した場所から最終的な色を求める方法ですが、色相バー(1次元)→彩度明度領域(2次元)→不透明度バー(1次元)の順に処理していきます。色相バーで選んだ色が彩度明度領域の右上の色になります。彩度明度領域は水平のグラデーション(左:白から右:色相選択色)の上に垂直グラデーション(上:透明黒から下:不透明黒)が重なっています。選んだ位置によって線形補間で水平、垂直の順で色を求めていきます。その色が今度は不透明度バーの上の色になって、最後に不透明度バーで選択した不透明度をその色に適用して完了です。仕組み自体はグラデーションの内容に依存していないので、色相、彩度、明度の軸を入れ替えても機能すると思いますし、1次元バーを緑、2次元領域を青と赤、などとしても大丈夫だと思います。(そのための切り替えUIを作るのが面倒くさかったのでやってませんが)
こうして出来たSVG画像はテキストプロパティまたはオーバーレイを使ってEmacs内に表示されます。というかEmacsではそれしか画像を表示する方法はありません(環境依存性の強い方法を除けば)。テキストプロパティでも良いのですが、オーバーレイの方がこういう用途では使いやすいでしょう。
オーバーレイにも画像を表示できる場所が三つあります。before-stringとdisplayとafter-stringです。displayはいいとして、before-stringとafter-stringですが、これはオーバーレイの前後に文字列を挿入するためのプロパティです。一見画像とは関係なさそうですが、この文字列にpropertize関数でdisplayテキストプロパティを適用するとオーバーレイの前後にさらに画像を表示することが可能になります。
これら色々ある表示方法を都合に合わせて選択できるように構造には柔軟性を持たせてあります。
先行事例を見てみると表示にフレームを使っているものがありました。普通のフレームを使っているものやchild frameという比較的最近のEmacsで使えるようになった仕組みを使っているものもありました。child frameを使うとフレーム内の好きな位置に重ねることが出来るのでポップアップで情報を出すパッケージで使われているようです。
とはいえフレームは扱いが難しく勉強が必要なので、とりあえずオーバーレイだけで出来る範囲で実装しています。
カラーピッカーはどこに表示すれば良いのでしょうか。だいたいポイント(やマウスカーソル)の近くですよね。ただ、ポイントの左や右にカラーピッカーのオーバーレイを挿入すると行が大きく膨らんで見づらくなってしまいますし、ウィンドウの左右からはみ出して見えなくなってしまうこともあります。となれば上の行か下の行に表示してはどうでしょう。上の行や下の行に適切な表示カラムが無いならどうすればいいでしょうか。幸いオーバーレイは行を新たに作ることが出来ます。before-string、display、after-stringの各プロパティにはそれぞれ文字列が指定できますが、いずれでも"\n"を入れることで改行が出来ます。例えば現在ポイントが20カラム目にあるとして、その真下付近に画像を表示するには、行末の改行文字にオーバーレイをかけて、before-stringを "\n " (←空白20個 - 画像の幅/2くらい)、displayに画像、after-stringに "\n" を指定してやればOKです。水平スクロールしている可能性があるのでwindow-hscrollの値を考慮するのを忘れずに。
また、ミニバッファに色を入力するようなシチュエーションでは画面の下の方にカラーピッカーを表示して欲しいです。いや、いっそのことミニバッファ内にカラーピッカーを入れたらどうでしょう。ここでもオーバーレイに改行させれば上をカラーピッカー、下を入力欄とすることが出来ます。ただし一つ注意点が。バッファの先頭にオーバーレイを入れたいわけですが、先頭の1文字にかけるとbefore-stringに画像を設定しなければならずその後に改行が入れられません。displayで改行すると1文字目が(改行に置き換わって)表示されなくなってしまいますし、after-stringで改行すると1文字目の後で改行されてしまいます。なので先頭の空の範囲((point-min)から(point-min)まで)にオーバーレイを設定します。注意点が二つ。evaporateプロパティがtだと空の範囲になった段階でオーバーレイが消えてしまいます。なのでevaporateは使わずちゃんとオーバーレイを管理する必要があります。もう一点は空の範囲のオーバーレイではdisplayプロパティが機能しないということ。before-stringとafter-stringは表示されるのですが、なぜかdisplayプロパティは空の範囲だと表示されません。なのでbefore-stringに画像を、after-stringに"\n"を指定することになります。(2021-09-07追記:よく考えたらbefore-stringの中で文字列の一部にだけdisplayプロパティをかけて、残りで改行すれば済むような気もします。未確認ですが、多分動くのではないかと)
他にもEmacsの色名とWeb(HTMLやCSS)の色名に対応するとか、色の表現形式とか、画像のスケーリングについてとか(上のスクリーンショット、ピッカーの大きさが違うのに気がつきましたか?)、色々書きたいことは山ほどありますが、この辺にしておきます。