Amazonのタイムセールで安く売っていたのでモバイルディスプレイを買いました。
-23%offで30785円と書いてありました(12/18)。今見たら39980円。
細かいモデル違いがあって、FHDか4Kか、タッチパネルに対応か非対応かの組み合わせで4モデルあるみたいです。私が買ったのはその中でFHDでタッチパネル対応のPFです。
一緒に買ったもの:
- MSI GT 710 2GD3H 4HDMI グラフィックスボード VD9284 (購入価格5080円)
- Mini HDMI - HDMIケーブル 2M、ウルトラスリム&フレキシブル HDMIミニケーブル (購入価格899円)
届いた後に「あ、ディスプレイ出力ポートが足りない!」とか「HDMIケーブルの長さがちょっと足りないなぁ」などと気がついて追加注文しました。
「ひょっとして電源スイッチがついてない?」とも思ったのですが、マニュアルを読んだら上下に操作できるつまみを2秒押すと電源のON/OFFができると書いてありました。これは分かりづらい。何かスイッチ付きケーブルが必要かと思って注文してしまいました……いや、電源OFFでも(画面は消えますが)タッチパネルが反応していますね。タブレットとして使うなら良いのかもしれませんがやっぱり電源スイッチの付きケーブルやハブはあった方が良いかも。
有機ELということで発色も綺麗ですしタッチやペンもしっかり機能してこれが3万円で買える時代になったことに驚くばかりです。
特殊なドライバーやユーティリティソフトなどは一切不要です。
グラカを追加してこれまでのディスプレイと併用したときに、タッチやペンが別のディスプレイに入力されてしまう問題が発生しましたが、コントロールパネル→ハードウェアとサウンド→タブレットPC設定から解決できました(Windows11)。普通の設定画面には関係しそうな項目は見当たりませんでした。
画面保護フィルムがグレアとノングレアの2枚が付属していました。その他付属品は充実していて必要そうな物は全部入っています。しかし13.3インチのパネルにフィルムを貼るのは滅茶苦茶難しいですね。ホコリがどうしても入ってしまいます。こりゃ風呂場で全裸かな。PDA工房で追加のフィルムを注文。
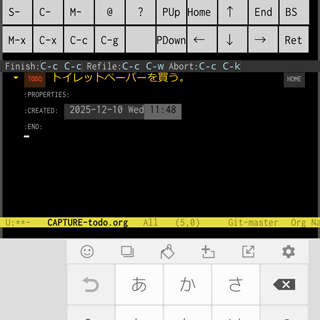
Emacsではちゃんとタッチイベント(touchscreen-begin、touchscreen-update、touchscreen-end)が発生しました。
ペン入力もEmacsはタッチイベントとして認識しているようでした。edrawをスタイラスで使ったときにおかしなマウスイベントが発生するという問題を聞いていたのでマウスイベントが発生するのかと思っていましたがこのあたりは環境によって変わってくるのだろうと思います。
Photoshopではちゃんと筆圧を認識しています。Emacsでは今のところ筆圧を取得する術は無いようです。もし取得できるようになってしまったら面倒ですね……。
何はともあれ、これでタッチイベントを使ったプログラムがメインのデスクトップPCでも効率よく開発できるようになりました。
メインのディスプレイ(24インチ)もタッチパネル付きだったらいいのになとも思っています。私はキーボード原理主義者ではないので目の前にボタンがあったら指で直接押せばいいじゃん、といつも思っています。とは言え今使っているディスプレイはまだまだ使えるので勿体ないですし余ったディスプレイを処分するのも面倒です。しばらくはこのままでいきましょう。